
L’entrainement d'un décodeur VAE modifié ainsi que l’affinage du modèle par rapport à un bruit modifié permettent de créer des images transparentes.

Stable Diffusion est un modèle de diffusion latente qui génère des images à partir d'un texte. Alors que nous voyons de nombreuses applications potentielles pour les modèles texte à image dans la production de jeux, nous sommes actuellement limités par l'incapacité des modèles à générer des images avec un canal alpha, ce qui est nécessaire pour les ressources graphiques telles que les icônes UX et les logos.
Dans cet article, nous expliquerons d'abord le pipeline existant de Stable Diffusion 1,5. Nous discuterons ensuite des trois modifications que nous avons apportées à ce réseau afin d'obtenir un résultat sensible à l'alpha : modification de la distribution du bruit sous-jacente du pipeline, affinage d’un réseau en U et entraînement d'un décodeur modifié.
Contexte
Au cours de l'entraînement, le modèle Stable Diffusion a été exposé à des milliards de paires image/texte RVB, qui ont été soumises à un processus de transformation en trois étapes :
- Encodage - conversion des images d'entraînement RVB en une représentation de “l'espace latent" de 4x64x64 via un encodeur 3x512x512 → 4x64x64
- Diffusion - ajout itératif de bruit aux images encodées, suivi d'un réseau en U de débruitage qui a appris à prédire le bruit ajouté (avec les informations supplémentaires du texte décrivant l'image) et à supprimer ce bruit de l'image
- Décodage - conversion des représentations latente d'images débruitées en leur format d'origine via un décodeur 4x64x64→3x512x512
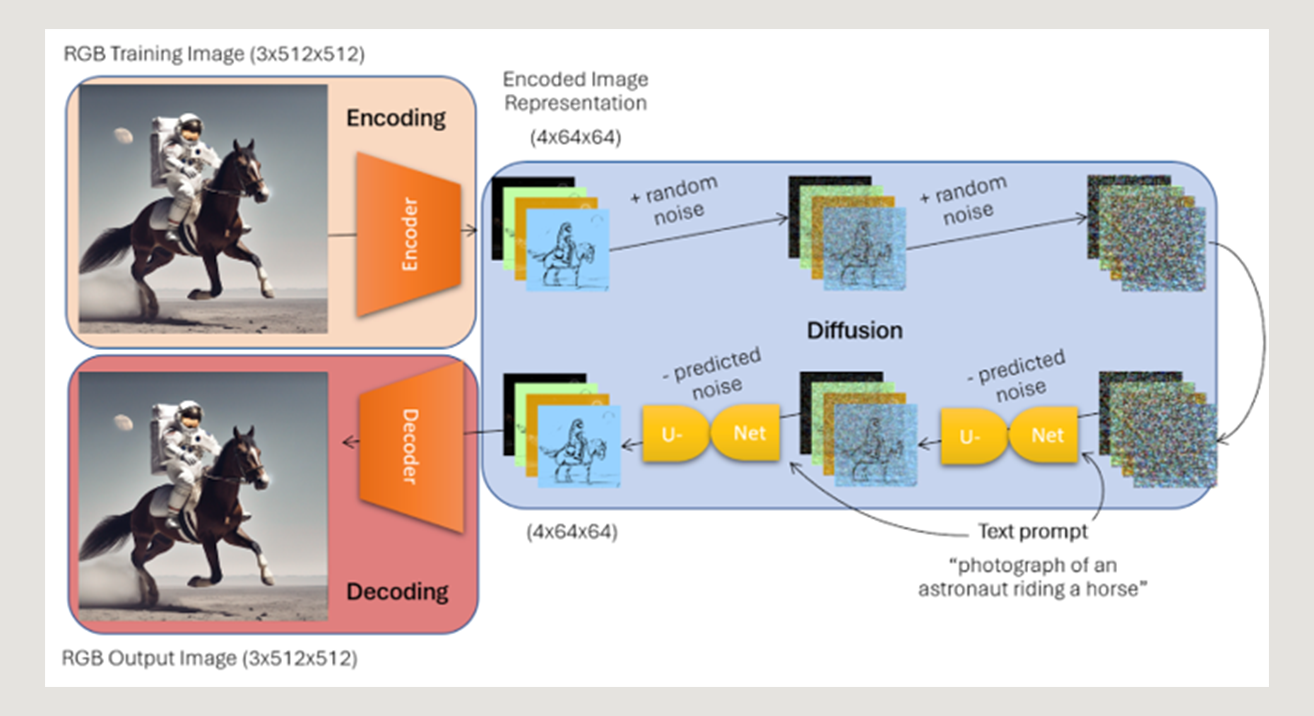
En entraînant Stable Diffusion à recréer les images d'apprentissage originales via élimination du bruit, le modèle a fini par comprendre comment générer des images à partir de bruit pur et d'une description textuelle, ce qui en a fait l'outil de référence qu'il est aujourd'hui.Une fois entraîné et étant donné un texte en entrée, la pipeline génère un patch aléatoire de bruit 4x64x64, et fait passer bruit et texte au travers du modèle en U pour débruiter de manière itérative le tenseur, puis le fait passer par le décodeur pour produire une image 3x512x512 correspondant à la description textuelle fournie.
Cependant, comme l’encodeur et le décodeur du modèle prennent en entrée et en sortie un espace de dimension 3x512x512, ce modèle, par définition, ne peut apprendre que la distribution sous-jacente des canaux rouge, vert et bleu des images, ce qui ne laisse pas de place à une compréhension innée du canal alpha.
Pourquoi modifier et ré-entraîner complètement le réseau est difficile ?
Une solution intuitive "facile" au dilemme du canal alpha consisterait à modifier la structure de l'encodeur et du décodeur du pipeline pour produire un quatrième canal qui encoderait l'information contenu dans le canal alpha (transparence) des images. Cependant, cela signifierait que le réseau en U devrait complètement réapprendre la distribution latente 4x64x64 des images pour comprendre comment encoder l’information du canal alpha - ce qui nécessiterait un réentraînement des trois réseaux (encodeur, réseau en U et décodeur) sur des milliards d'images. Ce réentraînement à grande échelle est extrêmement coûteux en ressources, c'est pourquoi nous avons expérimenté avec une solution à plus petite échelle qui laisse l'encodeur et le réseau en U pratiquement inchangés, et se concentre principalement sur le réentraînement d'un décodeur pour prédire un 4ème canal à partir de l'encodage d'image 4x64x64 déjà appris, ce qui a pris environ 2 minutes d'entraînement sur mon GPU Nvidia, grâce à l’utilisation de la technique d’affinage LORA pour le réseau en U de Stable Diffusion.
Modifications nécessaires du réseau
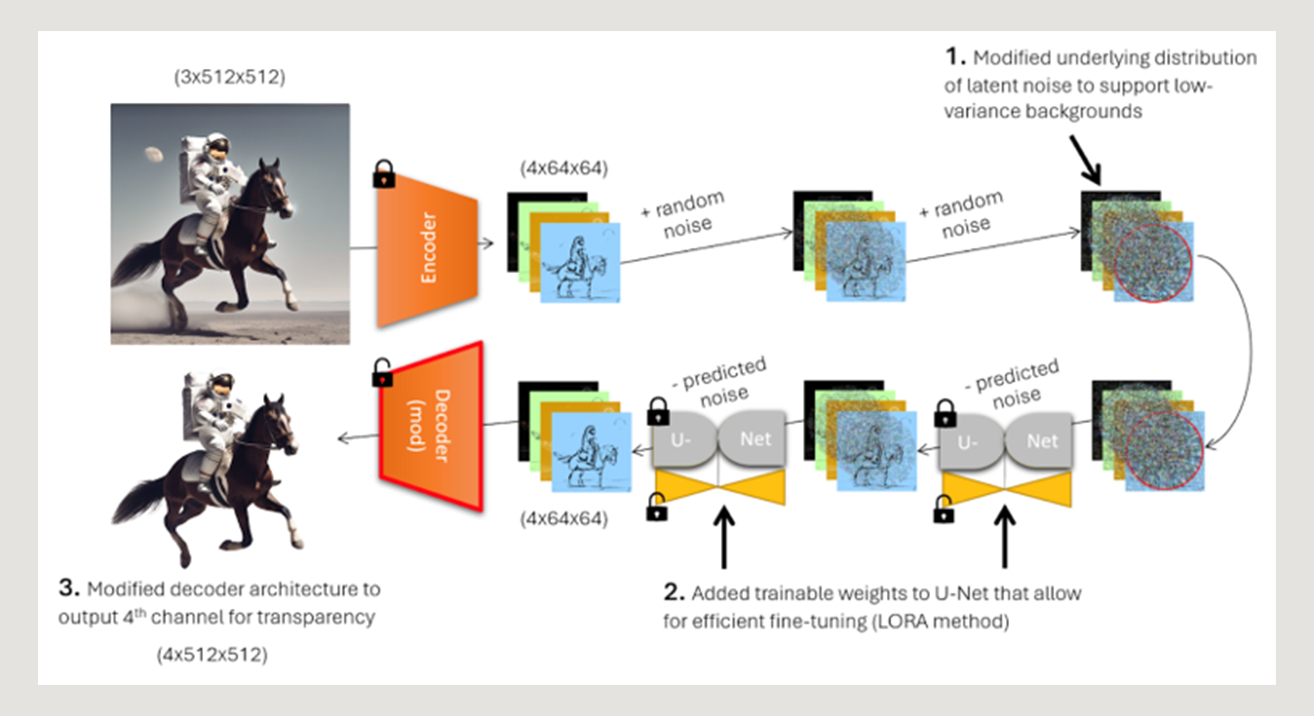
Les trois modifications que nous avons apportées au pipeline de Stable Diffusion afin d'encoder le canal alpha sont les suivantes :
- Modifier la distribution du bruit sous-jacent du modèle pour lui permettre de produire des objets centrés avec des arrière-plans à faible variance.
- Ajustement du modèle en U pour permettre au pipeline de reconnaître cette nouvelle distribution de bruit.
- Entraînement d'un décodeur modifié qui produit des images RVBA.
Modification de la distribution du bruit sous-jacent
Par défaut, Stable Diffusion génère des images à partir de valeurs de bruit initial distribuées uniformément, ce qui fait que les images de sortie résultantes présentent systématiquement une variance quelque peu uniforme sur l'ensemble de l'image. Toutefois, cela empêche le modèle de générer les valeurs de pixels homogènes nécessaires pour créer un arrière-plan transparent ou de couleur unie.

Pour permettre au pipeline de diffusion de produire des images d'avant-plan centrées et à forte variance avec des arrière-plans homogènes - une caractéristique déterminante des images RVBA avec des arrière-plans transparents - nous avons modifié la distribution initiale du bruit pour produire un bruit uniformément aléatoire dans un cercle au centre de la représentation latente de l’image, et un bruit décalé (décrit ici) ailleur.
Cela permet au pipeline de générer des avant-plans distincts avec des arrière-plans homogènes qu'il apprendra par la suite à identifier comme "transparents".


Affinage du réseau en U (LoRA) pour comprendre la nouvelle distribution du bruit
Après avoir modifié la distribution du bruit du pipeline de diffusion, l'étape suivante consistait à faciliter l’affinement LoRA pour permettre au modèle de mieux apprendre cette nouvelle distribution. Si vous n'êtes pas familier avec la méthode Low Rank Adaptation pour l’affinement des modèles, vous pouvez vous référer à l’article suivant Using LoRA for Efficient Stable Diffusion Fine-Tuning (huggingface.co).
Nous avons recueilli environ 100 images avec des arrière-plans blancs et avons effectué un affinage LoRA sur cet ensemble de données avec les images et leurs description textuelles suivies du mot-clé "no background" en utilisant ma nouvelle distribution de bruit. Cela a permis à Stable Diffusion de comprendre le nouveau modèle de bruit et de produire des images de premier plan centrées avec des arrière-plans de couleur unie, comme souhaité, après seulement 300 étapes d'apprentissage.
Apprentissage d'un décodeur à 4 canaux pour la sortie d'images RVBA
Enfin, nous devions entraîner un décodeur à prédire le canal alpha à partir d'une image avec un arrière-plan de couleur unie et de faible variance, ce que le pipeline de diffusion est désormais capable de produire.
Pour ce faire, nous avons modifié le VAE pré-entraînée de Stable Diffusion pour qu’il produise un quatrième canal codant l'information alpha (voir le code ci-dessous). Nous avons ensuite "gelé" les poids de l'encodeur de sorte que, pendant l'entraînement, seul le décodeur soit modifié et que la distribution latente apprise reste inchangée. Le modèle "prédit" alors essentiellement le canal alpha d'une image sur la base de sa représentation latente.
Python:
# Load Stable Diffusion's standard pretrainted Autoencoder,but modified to output a 4th channel
vae = AutoencoderKL.from_pretrained( "runwayml/stable-diffusion-v1-5", subfolder="vae", out_channels=4, low_cpu_mem_usage=False, ignore_mismatched_sizes=True).to("cuda")
# Only train the decoder weights, leave the encoder untouched to maintain the learned latent distribution
optimizer = torch.optim.Adam(vae.decoder.parametrs(),lr=1e-4)
Pour constituer un ensemble de données pour cette tâche, nous avons collecté 100 images avec des arrière-plans transparents, et nous avons augmenté ces images en un ensemble d'environ 2 000 images en appliquant des symmétries, rotations, zooms et augmentations de couleur aléatoires.
Chaque image d'entraînement RVBA a ensuite été augmentée dans une version à trois canaux d'elle-même, dans laquelle l'arrière-plan de l'image a été remplacé par un arrière-plan généré de manière aléatoire et à faible variance pour simuler les sorties possibles du pipeline de diffusion (voir l'image ci-dessous). Cette image à trois canaux a servi d'entrée au VAE modifié, qui a ensuite prédit l'image RVBA correspondante à partir de laquelle l'image RVB d'entrée a été dérivée.
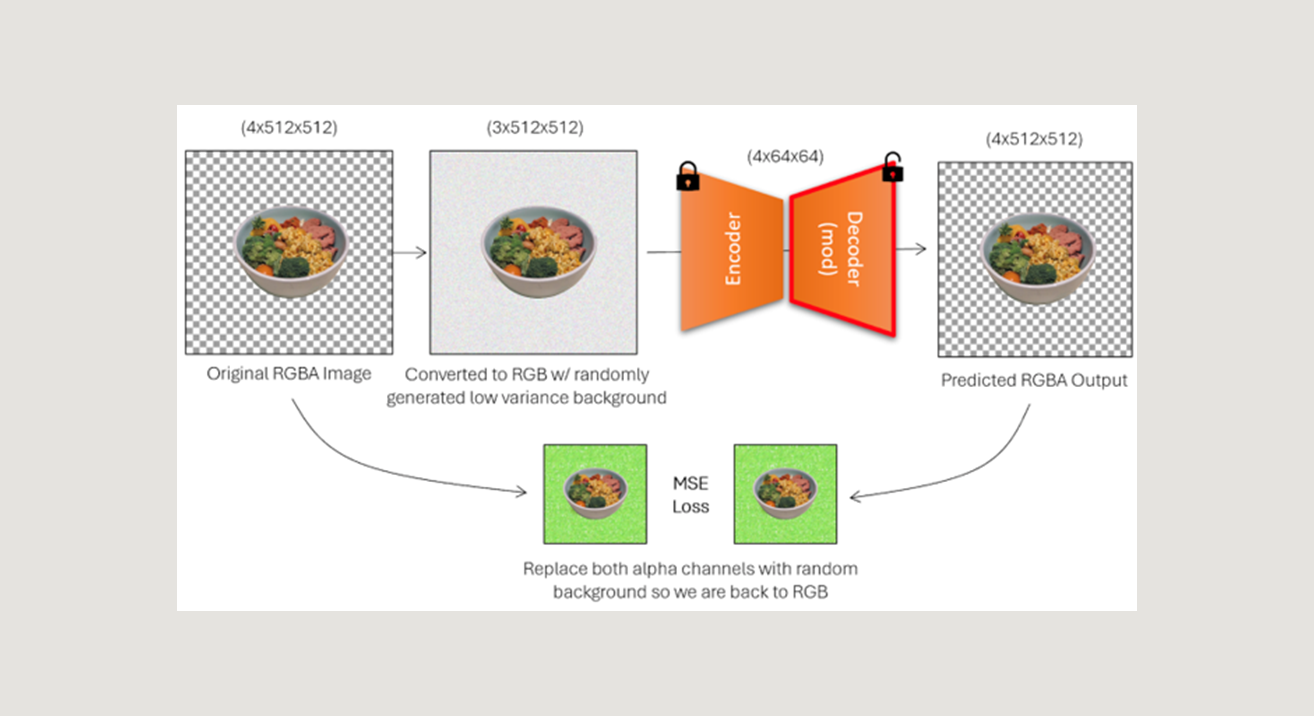
Au lieu d'utiliser la perte MSE standard entre l'image RVBA cible et les images RVBA de sortie, qui pondérerait de manière équivalente les pixels visibles et invisibles, nous avons créé une fonction de perte personnalisée qui correspond mieux à la similarité visuelle entre les images semi-transparentes.
Notre perte personnalisée a nécessité la création d'une autre image d'arrière-plan de couleur aléatoire et le "remplacement" des pixels transparents de chaque image par cet arrière-plan pour reconvertir les images dans l'espace RVB, où la perte MSE a ensuite été calculée. Cela a permis au modèle de ne considérer que les pixels visibles comme "importés" dans la reconstruction finale, et de produire de meilleurs résultats lors du décodage et de la prédiction du canal alpha.

Assembler le tout
Enfin, après affinage à partir du bruit modifié et l'entraînement d'un décodeur augmenté pour créer des prédictions de canal alpha à partir des représentations latentes, nous avons relié le nouveau réseau en U et le décodeur pour finaliser le pipeline modifié.
Python:
from diffusers import StableDiffusionPipeline
# Load the Stable Diffusion Pipeline
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, safety_checker=None)
# Load fine-tuned U-Net (LORA)
pipe.unet.load_attn_procs("path_to_lora_finetune")
# Load custom decoder (3-to-4)
vae = AutoencoderKL.from_pretrained(model_id, subfolder="vae", out_channels=4, low_cpu_mem_usage=False, ignore_mismatched_sizes=True).to("cuda")
vae.load_state_dict(torch.load("path_to_trained_autoencoder"))
pipe.vae = vae
pipe = pipe.to("cuda")
L'exécution de l'inférence sur ce pipeline modifié a permis de produire des images RVBA sans aucun post-traitement supplémentaire (voir les résultats ci-dessous).

Limites de la méthode
La principale limite de cette méthode est que le décodeur prédit un canal alpha à partir de la seule représentation latente de l'image et que, contrairement au réseau en U, il n'a pas accès au contexte de la description textuelle de l’image. Le décodeur peut donc assimiler les zones de faible variance à de la “transparence” sans avoir une compréhension plus profonde du type d'image qu'il produit. Cela peut poser un problème lors de la génération d'images de couleur homogène telles que des logos, où le décodeur peut incorrectement supprimer l'avant-plan à faible variance, ou lors de la production d'images semi-transparentes telles que des fenêtres et des tasses.

Contact
Annexe
Python:
import numpy as np
# Default noise initialization (uniform random)
normal_latents = randn_tensor((1, 4, 64, 64), generator=gen)
# Offset noise proposed by Diffusion With Offset Noise (crosslabs.org)
offset_latents = normal_latents + offset * randn_tensor((1, 4, 1, 1), generator=gen)
# Hybrid noise - normal at center, offset in background
hybrid_latents = normal_latents.clone()
max_dist_to_center = np.linalg.norm(np.array([32, 32])).item()
for i in range(64):
for j in range(64):
dist_to_center = np.linalg.norm(np.array([i, j]) - np.array([32, 32])).item()
ratio = dist_to_center / max_dist_to_center
if (ratio > 0.5): hybrid_latents[:,:,i,j] = offset_latents[:,:,i,j]