
Training a modified VAE decoder along with fine-tuning against modified noise enables the creation of transparent output images

Stable Diffusion is a latent diffusion model that generates images from text input. While we see many potential applications for text-to-image models in game production, we are currently limited by models’ inability to generate graphics with an alpha channel, which is required for graphic assets such as UX icons and logos.
In this post, we will first explain Stable Diffusion 1.5’s existing pipeline. We will then discuss the three modifications we made to this network in order to achieve alpha-aware output – modifying the underlying noise distribution of the pipeline, fine-tuning the U-Net, and training a modified decoder network.
Background
During training, the Stable Diffusion model was introduced to billions of RGB image / text pairs, which underwent a three-step transformation process:
- Encoding - converting the RGB training images into a 4x64x64 “latent space” representation via a 3x512x512 → 4x64x64 encoder
- Diffusion - iterative addition of noise to the encoded images followed by a denoising U-Net that learned to predict the noise that was added (with the additional information of the text prompt describing the image), and remove this noise from the image
- Decoding - converting the denoised image representations back to their original image format via a 4x64x64→3x512x512 decoder
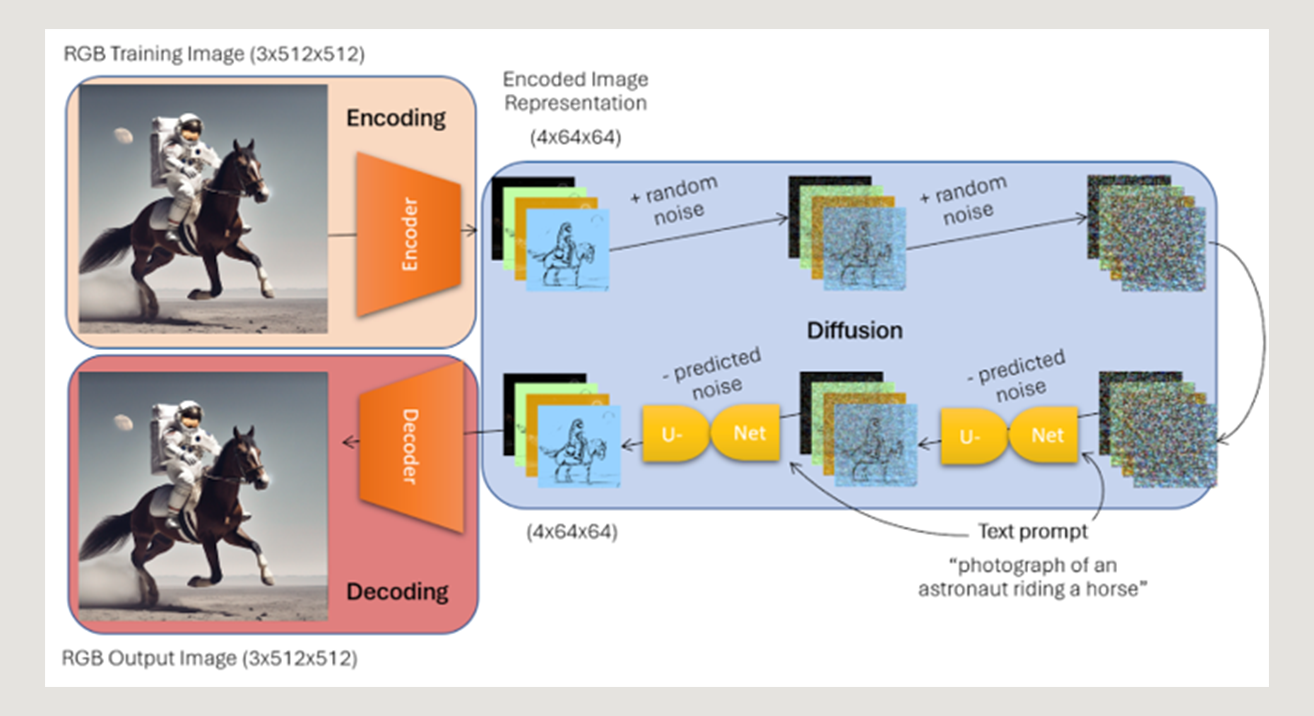
By training Stable Diffusion to recreate the original training images through noise removal, the model eventually gained the ability to understand how to generate images from pure noise and a text description – making this the landmark tool it is today. Now, provided a text prompt as input, the pipeline generates a random patch of 4x64x64 noise, and runs this noise and text through the U-Net to iteratively denoise the tensor, then pass this through the decoder to output a 3x512x512 image fitting the text description provided.
However, because the model’s encoder and decoder convert to and from the 3x512x512 space, this model by nature was only able to learn the underlying distribution of images’ red, green, and blue channels, leaving no room for an innate understanding of “alpha”.
Why Complete Network Modification and Retraining is Difficult
An “easy” intuitive solution to the alpha channel dilemma would be to modify the encoder and decoder structure of the pipeline to produce a 4th channel that would encode alpha (transparency) information about images. However, this would mean that the U-Net would have to completely relearn the 4x64x64 latent distribution of images to understand how to encode alpha - requiring retraining all three networks (encoder, U-Net, decoder) on billions of images. This full–scale retraining is extremely resource-intensive, so we experimented with a smaller-scale solution that leaves the encoder and U-Net mostly unchanged, and focuses mainly on retraining a decoder to predict a 4th channel from the already learned 4x64x64 image encoding, which took about 2 minutes worth of training on my Nvidia GPU, along with an efficient LORA finetune of Stable Diffusion’s U-Net.
Required Network Modifications
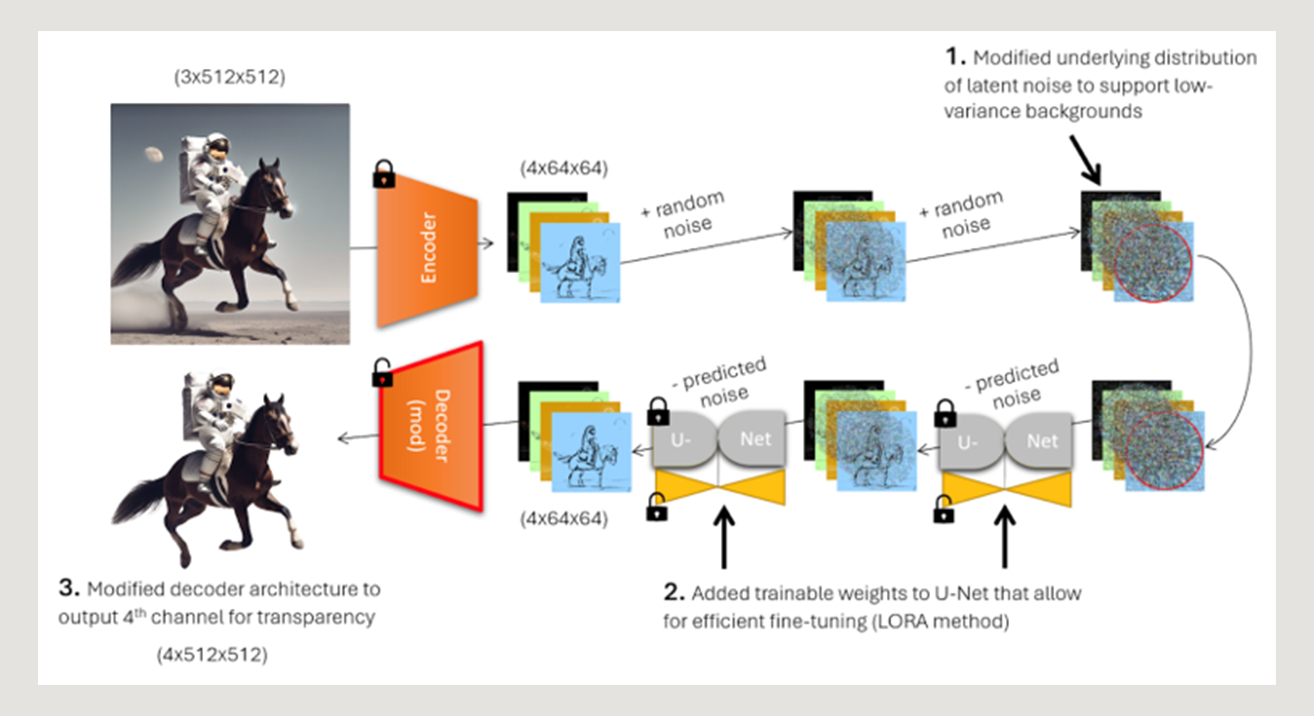
The three modifications we made to the Stable Diffusion pipeline in order to encode alpha capabilities were:
- Modifying the underlying noise distribution of the model to enable it to output centered objects with low-variance backgrounds
- Fine-tuning the U-Net to allow the pipeline to recognize this new noise distribution
- Training a modified decoder that outputs RGBA images
Modifying the Underlying Noise Distribution
By default, Stable Diffusion generates images from uniformly random values of initial noise, which causes the resulting output images to consistently exhibit variance somewhat evenly throughout the entire image. However, this prevents the model from being able to generate the homogeneous pixel values necessary to create a proper transparent or solid-colored background.

To enable the diffusion pipeline to produce centered, high variance foreground images with homogeneous backgrounds – a defining feature of RGBA images with transparent backgrounds – we modified the initial noise distribution to produce uniformly random noise in the innermost circle of the latents, and offset noise (described here) in the remainder of the space.
This allows the pipeline to generate distinct foregrounds with homogeneous backgrounds that it will eventually learn to identify as “transparent”.


Fine Tuning the U-Net (LoRA) to Understand the New Noise Distribution
After modifying the noise distribution of the diffusion pipeline, the next step was facilitating a LoRA finetune to allow the model to better learn this new distribution. If you are unfamiliar with the Low Rank Adaptation method for model fine tuning, see Using LoRA for Efficient Stable Diffusion Fine-Tuning (huggingface.co).
We collected ~100 images with plain white backgrounds and ran a LoRA finetune on this dataset with the images and their corresponding text prompts followed by the keywords “no background” using my new noise distribution. This enabled Stable Diffusion to understand the new noise pattern and produce centered foreground images with plain-colored backgrounds as desired after only around 300 steps of training.
Training a 4-channel Decoder to Output RGBA Images
Finally, we needed to train a decoder to predict the alpha channel from an image with a plain-colored, low variance background, which the diffusion pipeline was now capable of producing.
To accomplish this, we modified Stable Diffusion’s pretrained VAE to output a 4th channel encoding alpha information (see code below). We then “froze” the encoder weights so that during training, only the decoder would be modified and the learned latent distribution would be unchanged. The model then essentially “predicts” the alpha channel of an image based on its latent representation.
Python:
# Load Stable Diffusion's standard pretrainted Autoencoder,but modified to output a 4th channel
vae = AutoencoderKL.from_pretrained( "runwayml/stable-diffusion-v1-5", subfolder="vae", out_channels=4, low_cpu_mem_usage=False, ignore_mismatched_sizes=True).to("cuda")
# Only train the decoder weights, leave the encoder untouched to maintain the learned latent distribution
optimizer = torch.optim.Adam(vae.decoder.parametrs(),lr=1e-4)
To formulate a dataset for this task, we collected 100 images with transparent backgrounds, and augmented these images into a set of around 2,000 images by applying random flips, rotations, zooms, and color augmentations.
Each RGBA training image was then augmented into a 3-channel version of itself, wherein the image’s background was replaced with a randomly generated, low-variance background to simulate possible outputs from the diffusion pipeline (see image below). This 3-channel image served as the input to the modified VAE, which then predicted the corresponding RGBA image from which the input RGB image was derived.
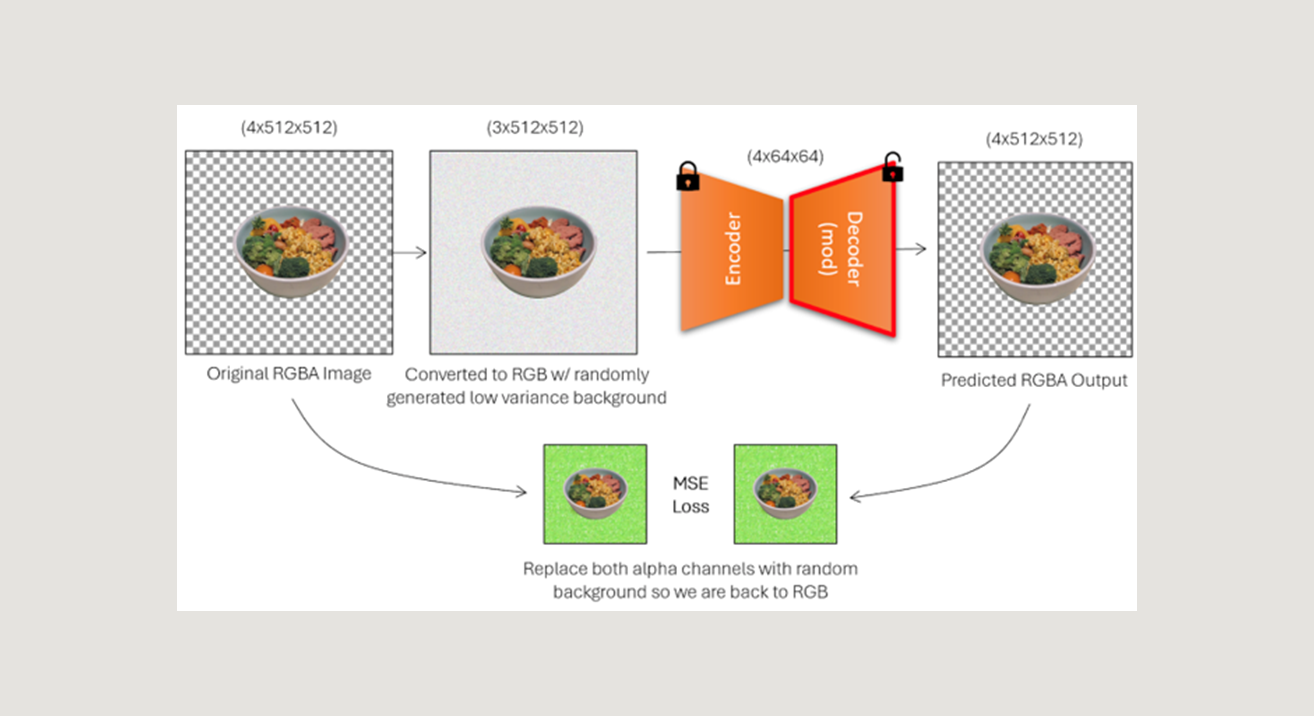
Instead of using standard MSE loss between the target RGBA image and output RGBA images, which would equally weight visible and non-visible pixel values, we created a custom loss function that more closely corresponds to the visual similarity between semi-transparent images.
Our custom loss required creating another random colored background image, and “replacing” each image’s transparent pixels with this background to convert the images back to the RGB space, where MSE loss was then calculated. This allowed the model to just weight visible pixels as “import” in the final reconstruction, and produce better results during decoding and alpha channel prediction.

Putting Everything Together
Finally, after fine-tuning on modified noise and training an augmented decoder to create alpha channel predictions from latents, we tied together the new U-Net and decoder to finalize the modified pipeline.
Python:
from diffusers import StableDiffusionPipeline
# Load the Stable Diffusion Pipeline
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, safety_checker=None)
# Load fine-tuned U-Net (LORA)
pipe.unet.load_attn_procs("path_to_lora_finetune")
# Load custom decoder (3-to-4)
vae = AutoencoderKL.from_pretrained(model_id, subfolder="vae", out_channels=4, low_cpu_mem_usage=False, ignore_mismatched_sizes=True).to("cuda")
vae.load_state_dict(torch.load("path_to_trained_autoencoder"))
pipe.vae = vae
pipe = pipe.to("cuda")
Running inference on this modified pipeline was now able to output RGBA images without any extra post-processing (see results below).

Method Limitations
The major limitation with this method is that the decoder predicts an alpha channel from the image’s latent representation only, and unlike the U-Net, does not have access to the context of the text prompt itself. This can cause the decoder to equate areas of low variance to “transparency” possibly without a deeper underlying understanding of the type of image it produces. This may pose an issue generating homogeneous-colored output like logos, where the decoder may improperly remove the low-variance foreground, or with semi-transparent output like windows and cups.

Contact
Appendix
Python:
import numpy as np
# Default noise initialization (uniform random)
normal_latents = randn_tensor((1, 4, 64, 64), generator=gen)
# Offset noise proposed by Diffusion With Offset Noise (crosslabs.org)
offset_latents = normal_latents + offset * randn_tensor((1, 4, 1, 1), generator=gen)
# Hybrid noise - normal at center, offset in background
hybrid_latents = normal_latents.clone()
max_dist_to_center = np.linalg.norm(np.array([32, 32])).item()
for i in range(64):
for j in range(64):
dist_to_center = np.linalg.norm(np.array([i, j]) - np.array([32, 32])).item()
ratio = dist_to_center / max_dist_to_center
if (ratio > 0.5): hybrid_latents[:,:,i,j] = offset_latents[:,:,i,j]